| 子程序名 | 返回值类型 | 公开 | 备 注 | ||||
| 文本_取全部汉字拼音 | 文本型 | 支持取出文本中所有国标汉字的拼音,默认不保留非国标汉字字符。 | |||||
| 参数名 | 类 型 | 参考 | 可空 | 数组 | 备 注 | ||
| 文本 | 文本型 | 欲取拼音的文本 | 保留非汉字 | 逻辑型 | 默认假,不保留原文本里的符号和数字等非国标汉字字符;真则保留。 | ||
| 变量名 | 类 型 | 静态 | 数组 | 备 注 | ||
| b | 字节集 | |||||
| c | 整数型 | |||||
| n | 整数型 | |||||
| z | 整数型 | |||||
| ret | 文本型 | |||||
| p0 | 文本型 | |||||
| p1 | 文本型 | |||||
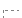 如果真 (是否为空 (保留非汉字))
如果真 (是否为空 (保留非汉字))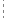 保留非汉字 = 假
保留非汉字 = 假b = 到字节集 (文本)
c = 取字节集长度 (b)
n = 1
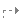 判断循环首 (n ≤ c)如果 (n > c)
判断循环首 (n ≤ c)如果 (n > c)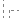 z = 1
z = 1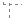
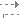 如果 (b [n] > 128)
如果 (b [n] > 128) z = 2p0 = 到文本 (取字节集中间 (b, n, 2))p1 = 取拼音 (p0, 1)判断 (取文本长度 (删全部空 (p1)) ≠ 0)ret = ret + p1 + “空”如果真 (保留非汉字)ret = ret + p0
z = 2p0 = 到文本 (取字节集中间 (b, n, 2))p1 = 取拼音 (p0, 1)判断 (取文本长度 (删全部空 (p1)) ≠ 0)ret = ret + p1 + “空”如果真 (保留非汉字)ret = ret + p0
 如果 (b [n] ≠ 13)z = 1如果 (b [n + 1] = 10)z = 2
如果 (b [n] ≠ 13)z = 1如果 (b [n + 1] = 10)z = 2 z = 1如果真 (保留非汉字)如果 (取文本长度 (删全部空 (取拼音 (到文本 (取字节集中间 (b, n + 1, 2)), 1))) ≠ 0) ' ‘判断单字节字符后面是否是双字节字符ret = ret + 到文本 (取字节集中间 (b, n, z)) + “空”ret = ret + 到文本 (取字节集中间 (b, n, z))n = n + z
z = 1如果真 (保留非汉字)如果 (取文本长度 (删全部空 (取拼音 (到文本 (取字节集中间 (b, n + 1, 2)), 1))) ≠ 0) ' ‘判断单字节字符后面是否是双字节字符ret = ret + 到文本 (取字节集中间 (b, n, z)) + “空”ret = ret + 到文本 (取字节集中间 (b, n, z))n = n + z 判断循环尾 ()
判断循环尾 ()ret = 子文本替换 (ret, “ ”, “”, , , 真) ' ’删除中间多余的空格
ret = 子文本替换 (ret, “空”, “ ”, , , 真) ' ’把用作隔开的“空”替换为“ ”
如果真 (取文本右边 (ret, 1) = “ ”) ' ’删除尾部多余空格ret = 取文本左边 (ret, 取文本长度 (ret) - 1)返回 (ret)
词条作者信息 使用例程